Oxford Nanopore Tech Update: new Duplex method for Q30 nanopore single molecule reads, PromethION 2, and more
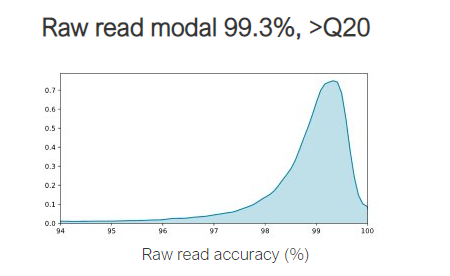
- In a technical update at the London Calling 2021 conference, Oxford Nanopore provided an overview of recent platform advances, including modal single-read accuracy of >99.3% using “Q20+” chemistry and a range of basecalling and library preparation methods to suit broad applications. The Q20+ kits are working in the hands of a small group of developers and will be released into early access soon
- ‘Duplex’ was introduced, a new method that has shown single molecule accuracy trending towards Q30 (99.9%) in internal experiments, to be released soon
- The upcoming product pipeline includes a new device, the PromethION 2, enabling broader access to high output nanopore sequencing and ‘Outy’, an alternative ‘direction’ of sequencing with multiple potential advantages.
Basecalling and performance update
Data yields: A key R&D goal for Oxford Nanopore is to drive optimised data output, so that users can achieve cost-effective experiments at any scale. Multiple improvements to PromethION flow cells were released in late 2020, and following a record breaking PromethION run in December 2020, where 10Tb of data was produced on a single PromethION 48 run, a recent customer record was set of 245Gb from a single flow cell.
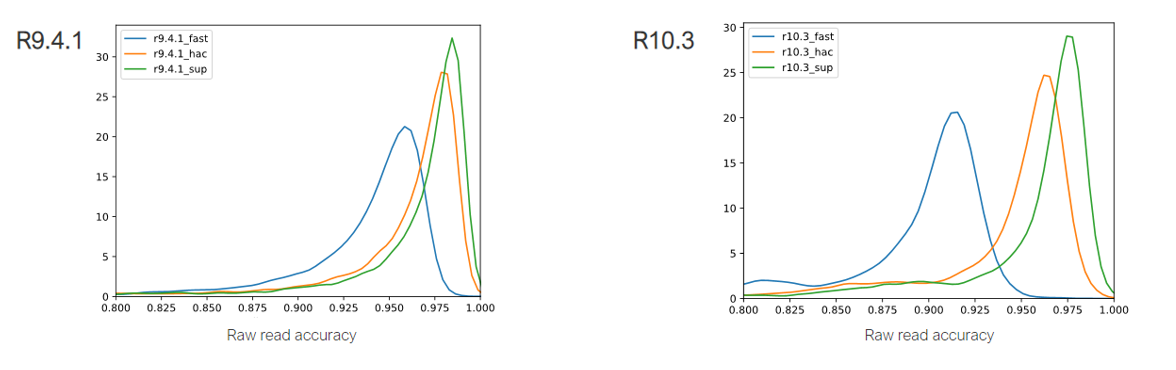
Current basecalling options: In late 2020, a new improved basecaller was released into early access, producing modal raw read accuracies of 98.3%. This basecaller, Bonito is now integrated into the standard Guppy and MinKNOW operating software for everyday use. Basecalling options are:
- Fast basecalling - where analysis keeps up on all Oxford Nanopore devices. Modal raw read accuracy in this mode is nearly 96%, broadly equivalent to the performance of our high accuracy models two years ago
- High accuracy – a good balance of performance and accuracy, that can deliver 97.8% raw read accuracy
- Super accuracy – the standard architecture from Bonito research basecaller, which can achieve 98.3% raw read accuracy
For users who wish to run more samples in higher accuracy modes and would like to add compute capacity, Oxford Nanopore is collaborating with Nvidia to supply the DGX station A100 so users who need extra compute can come to Oxford Nanopore for 2.5 petaflops of compute for a reasonable list price.
Oxford Nanopore is planning to reintroduce the option to basecall in the cloud with EPI2ME, and will provide further information on this soon.
Variant calling: beyond raw read accuracy, nanopore sequencing now offers comprehensive, highly accurate characterisation of genetic variants, and highly contiguous genomes. Using the latest tools, users can achieve SNV accuracy of 99.9%, Human assemblies of Q47 (80Mb N50), bacterial assemblies of Q50 (circular), SV detection at 96% and methylation equivalent to bisulfite. For more information on the tools and methods that can support a range of different types of accuracy please visit our accuracy pages.
Q20+ chemistry: In early 2021, a new nanopore chemistry called “Q20+” was released to developer users, who have been generating >99% modal raw read accuracy. Q20+ uses a refined motor enzyme with better movement quality, and is typically used with R10 flow cells and the Bonito basecaller. Oxford Nanopore expanded Q20+ availability from Developer phase to Early Access.
Update: During the Nanopore Community Meeting 2021, Oxford Nanopore released the Kit 12 chemistry for a range of sample preparation approaches: Read more about how to access the latest Q20+ kits
Q20+ will initially be available for MinION and GridION; PromethION users may require a hardware upgrade, which will begin in the summer. Please get in touch here for your upgrade.
New chemistry: Duplex. Oxford Nanopore announced a new method, “Duplex” which enables nanopore devices to sequence a template and complement strand of a single molecule of DNA, in succession, in order to achieve very high accuracy sequencing results. This system can currently achieve modal accuracy trending towards Q30 for a single double stranded molecule of DNA. The goal of Duplex experiments is to achieve a high proportion of instances where the complement follows the template strand through the nanopore and gives the system ‘two looks at the same sequence pairs’. Current runs are routinely achieving 40% of data from Duplex pairs, with 50% the current highest and 75% is targeted after further optimisation.
Duplex is compatible with the ultra-long kit capable of N50s greater than 100kb, with some further optimisation required. The longest Duplex molecule sequenced to Q30 to date is 146kb. Duplex is currently in developer phase as an extension of the Q20+ chemistry release programme.
Requiring only two reads the Duplex system is designed to enable users to generate high accuracy, long native reads with methylation information whilst not having to sacrifice output to high depth consensus methods.
Analysis: EPI2ME. In order to support a range of users, from those who prefer more automated analyses to those who prefer more bioinformatic visibility, Oxford Nanopore is expanding its range of EPI2ME solutions. EPI2ME offers a range of analyses from assembly, exome alignment and real-time species ID with What’s in my Pot (WIMP), to most recently the ARTIC protocol for SARS-CoV-2 analysis. EPI2ME Labs offers tutorials on how to get the optimal performance and data handling techniques for a range of workflows. For those who wish to scale these methods, EPI2ME Labs Workflows are now deployed using Nextflow for scaled analysis solutions.
Sample preparation: VolTRAX update: Since NCM2020 we have continued work on SARS-CoV2 library preparation with VolTRAX, and have now seen results for this replicated in Developer’s hands. As this requires a PCR-enabled device VolTRAX V2b will shortly be available, with PCR functionality correctly calibrated. In conjunction with this a new “Blue” cartridge is being introduced with initial programming for RT-PCR SARS-CoV2 sequencing, and simplified priming fluid integration. All VolTRAX users can now register for their VolTRAX V2b upgrade, scheduled to begin in Q3 2021.
Native barcoding: With native barcoding for the kit 10 fuel fix adapter, our approach is now moving away from an expansion-pack format and instead bringing 24 barcodes and the components required for sequencing into a single kit. Following customer feedback we will then be following this with 96 native barcodes in a single-use plate, which will begin to ship in late summer. With the plate format, 96 samples can be multiplexed on a single PromethION flow cell at the cost of £10 per sample.
Ultra-long reads: Nanopores will process the fragment presented in the library, whether short, long or ultra long. As experiments with long and ultra long fragments can provide richer biological insights, Oxford Nanopore continuously works to improve sequencing methods to support long read libraries. The Ultra-Long read kit, launched in spring 2021 with Circulomics, utilises transposase chemistry to maximise long reads. In an internal run, a record single read of 4.15Mb spanned >6000 SNPs, 125 SVs and >32,000 CpGs.
R&D Pipeline
Pipeline devices and consumables: PromethION 2. A new device, PromethION 2, will offer very high throughput sequencing in a shoebox-size device. With the ability to run one or two PromethION flow cells at a time, and integrated compute, the $60k starter pack would include 48 flow cells for easily accessible, compact and powerful sequencing. Oxford Nanopore is targeting 2022 availability.
Update: It was announced at the Nanopore Community Meeting 2021 that P2 and P2 Solo are now available to pre-order via the Nanopore store.

Pipeline devices and consumables: Next Generation Flongle. With a goal of very low-cost flow cells, the R&D teams at Oxford Nanopore have been developing new flow cells for the Flongle adapter, based on a polymer rather than silicon substrate. This new material, alongside using silver chloride, offers a range of potential benefits including lower noise, lower manufacturing costs and stable currents for long run times. Proof of concepts are showing good accuracy, and work is now scaling up.
Pipeline devices and consumables: ‘Voltage chip’. Voltage sensing is a paradigm shift of how a nanopore current can be collected, enabling denser sensors – where channels are engineered with 40uM spacing - for much higher throughput flow cells at the same size chip. Work continues using the new prototype ASICS; current designs have the potential to enable a human genome flow cell cost of as little as $10.
Pipeline devices and consumables: new ASICs for new devices: Work is ongoing on low power ASICs, that would support product lines such as SmidgION (mobile phone sequencing) and Plongle (multi-sample)
Pipeline chemistry: Inny and Outy. Current nanopore chemistries sequence DNA as it is driven from the ‘top’ of the flow cell through the nanopore to the area underneath; this is known as ‘Inny’. However, there are many potential benefits of deploying the opposite ‘outy’ direction, one format being where DNA threads from the ‘three prime’ (3’) end first, still moving 5’ to 3’. The different DNA orientation may produce a different error profile, with options for controlling the motor speed by changing the voltage. After the squiggle signal is generated, the DNA can be kept at the nanopore until it is ejected. This has the potential to enable approximate fragment sizing before sequencing – and therefore enable pre-selection of the desired read lengths. The method can also be used to perform controlled re-reading of native strands.
In internal experiments, single pass accuracy is currently at ~93% travelling at 190 bases per second through the pore. The R&D teams are currently progressing through iterative nanopore and enzyme designs to further improve the method.
Also presented was the potential for new on-flowcell size selection methods, using enzyme-free threading of the template strand through the pore to permit sizing of the fragment length. If the fragment is of the desired size, the enzyme moves through the complement to sequence the fragment; if not the pore rejects the strand. An N50 increase from 30 kb to 61 kb using this method has been demonstrated
Oxford Nanopore is currently exploring combining Adaptive Sampling – real-time acceptance or rejection of molecules from a nanopore based on sequence or signal – to enrich/deplete the sample for specific targets of interest – with ultra-long sequencing, in Q20+ accuracy conditions. In addition, “Adaptive finishing” would make it possible to reach even coverage and finishing faster, by by proactive selection of ultra-long fragments that covered regions of low, or no coverage.
Clive Brown - Nobody Expects the Strandish Exposition
James Clarke, Stuart Reid and Rosemary Dokos - Oxford Nanopore technology update






