Benchmarking of de novo assembly algorithms for Nanopore data reveals optimal performance of OLC approaches.
- Published on: August 22 2016
- Source: BioMed Central
Background
Improved DNA sequencing methods have transformed the field of genomics over the last decade. This has become possible due to the development of inexpensive short read sequencing technologies which have now resulted in three generations of sequencing platforms. More recently, a new fourth generation of Nanopore based single molecule sequencing technology, was developed based on MinION sequencer which is portable, inexpensive and fast. It is capable of generating reads of length greater than 100 kb. Though it has many specific advantages, the two major limitations of the MinION reads are high error rates and the need for the development of downstream pipelines. The algorithms for error correction have already emerged, while development of pipelines is still at nascent stage.
Results
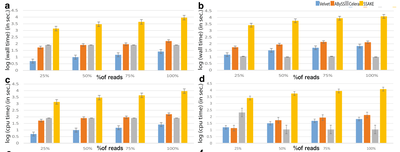
In this study, we benchmarked available assembler algorithms to find an appropriate framework that can efficiently assemble Nanopore sequenced reads. To address this, we employed genome-scale Nanopore sequenced datasets available for E. coli and yeast genomes respectively. In order to comprehensively evaluate multiple algorithmic frameworks, we included assemblers based on de Bruijn graphs (Velvet and ABySS), Overlap Layout Consensus (OLC) (Celera) and Greedy extension (SSAKE) approaches. We analyzed the quality, accuracy of the assemblies as well as the computational performance of each of the assemblers included in our benchmark. Our analysis unveiled that OLC-based algorithm, Celera, could generate a high quality assembly with ten times higher N50 & mean contig values as well as one-fifth the number of total number of contigs compared to other tools. Celera was also found to exhibit an average genome coverage of 12 % in E. coli dataset and 70 % in Yeast dataset as well as relatively lesser run times. In contrast, de Bruijn graph based assemblers Velvet and ABySS generated the assemblies of moderate quality, in less time when there is no limitation on the memory allocation, while greedy extension based algorithm SSAKE generated an assembly of very poor quality but with genome coverage of 90 % on yeast dataset.
Conclusion
OLC can be considered as a favorable algorithmic framework for the development of assembler tools for Nanopore-based data, followed by de Bruijn based algorithms as they consume relatively less or similar run times as OLC-based algorithms for generating assembly, irrespective of the memory allocated for the task. However, few improvements must be made to the existing de Bruijn implementations in order to generate an assembly with reasonable quality. Our findings should help in stimulating the development of novel assemblers for handling Nanopore sequence data.






