Interview: The PromethION Experts at VIB
![]()
with Mojca Strazisar, Tim De Pooter and Wouter De Coster, members of the VIB Center for Molecular Neurology
Conducted and written by Jonathan Pugh
“Yields have been exploding in the past few months again. We were in the beginning very happy to hit 50 gigabases, now we’re getting to 180 gigabases”
Wouter De Coster of the VIB Center for Molecular Neurology on the yield from individual flow cells of their PromethION, a device capable of running up to 24 or 48 flow cells depending on model.
The PromethION from Oxford Nanopore Technologies has developed in a short space of time into a device with unrivalled output in the DNA and RNA sequencing space. However, it hasn’t evolved in isolation, regular enhancements to software, hardware, chemistry and basecalling algorithms has kept it at the forefront of what you can do with nanopore sequencing at scale. As with all Oxford Nanopore sequencing devices, these upgrades have been provided as part of their ongoing usage, with no additional device purchase required.
Anyone who has experienced and worked with every one of these iterative improvements will undoubtedly be an expert in their own right. Indeed, when I spoke with the team at the VIB Center for Molecular Neurology it was clear they understood just how valuable their expertise is.
The team lead of the Neuromics Support Facility at VIB-UAntwerp, Mojca Strazisar, commented that they know the technology so well because “we’ve had some time to get experienced with it”. This is an understatement; VIB joined the PromethION Early Access Programme in 2016, received their first configuration device in early 2017, then went on to use the Alpha, Beta, and now PromethION 24 (P24) versions of the device (a version with 48 flow cell positions is also available). Present throughout this time has been her team member and expert technician Tim De Pooter, and a power user of the device’s data Wouter De Coster, a bioinformatician postdoc in the lab of Rosa Rademakers.
The right length of long read
Tim commented how keenly they awaited the arrival of their P24: “we planned to start with the big brain project around that time and we wanted to make sure to sequence everything on the same device”. The ‘big brain project’ refers to 200 brain tissue samples being sequenced as part of a study into frontotemporal dementia (FTD), a subtype of dementia with a relatively early typical onset at <65 years of age and characterised by language or behavioural impairments. This is Wouter’s main project, for which he gave an update at the Nanopore Community Meeting in December 2020.
“we know that we can look at parental imprinting, that we can identify loci which are methylated on one strand but not the other…we know that it’s all in the data"
Wouter’s aims are two–fold, using native DNA samples firstly “to discover structural variants, and the secondary aim would be to discover nucleotide modifications such as methylation and hydroxymethylation”. Wouter’s work has identified a read-length “sweet spot” for this project of around 15–20 kb, at which sequencing yields are maximised and the highest number of structural variants (SVs) are detected. The long reads then allow him to phase and “look for haplotype-specific loss or gain of nucleotide modifications, … we know that we can look at parental imprinting, that we can identify loci which are methylated on one strand but not the other, … we know that it’s all in the data”. Once the sequencing of all samples is complete, he plans to analyse them all together, so his response to my question regarding using the modification data to discover new insights is “ask this question again in two months!”.
Knowing the sweet spot for sequencing extends beyond SV detection, and when I ask about library preparation it’s clear Tim is 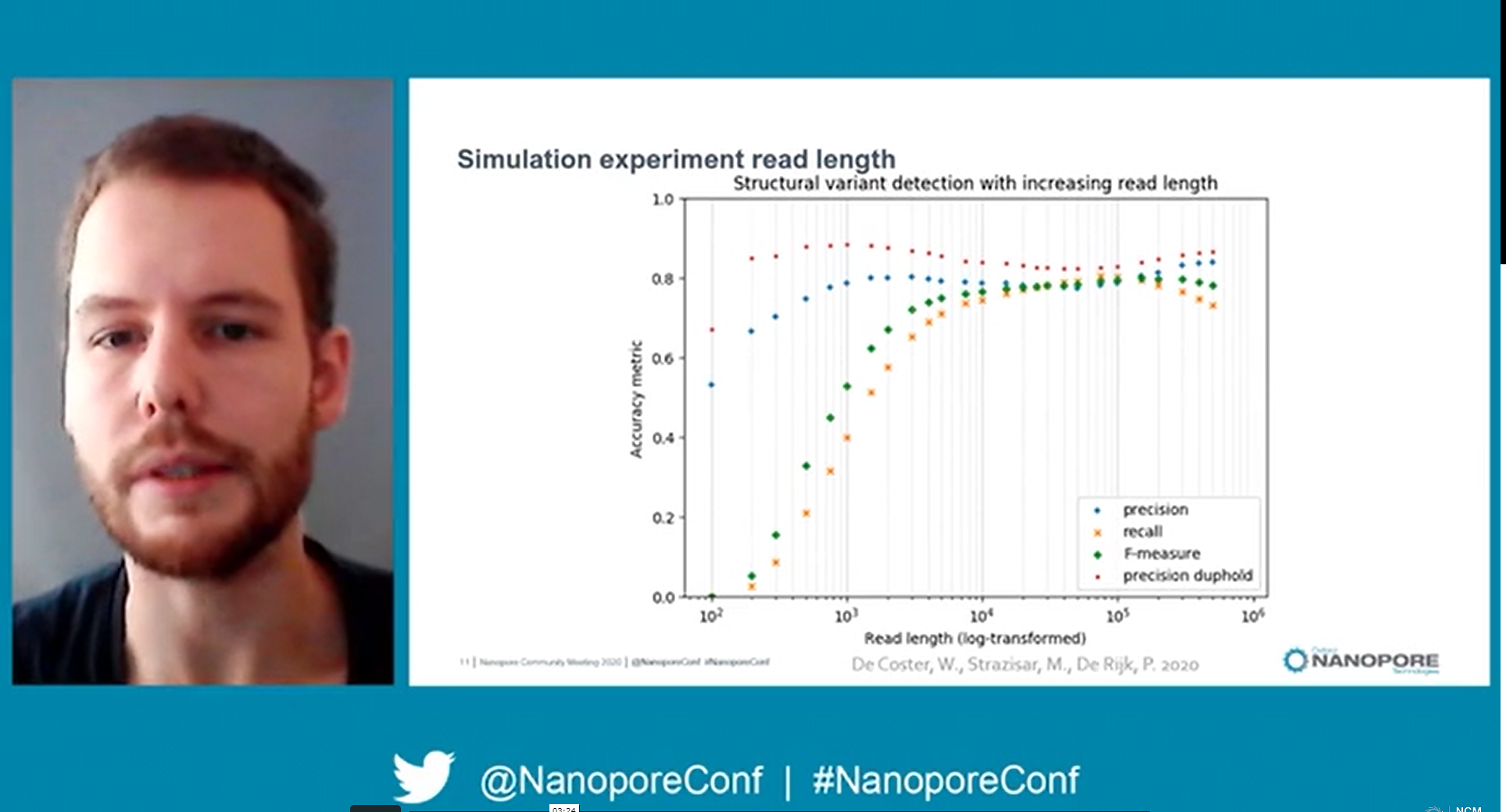 very thorough with his work to ensure he has absolute confidence in every sample. “UV-Vis, fragment analyser, and Qubit. Several times” is his simple answer when I inquired what sample QC methods they used prior to sequencing. Mojca elaborated further by saying “sample prep can include shearing, size selection, short read eliminator* … all of these segments are QC’d in the library prep”. With all these checks in place, and from their vast experience they understand if a collaborator’s sample won’t sequence well and where needed the team will “go back to the collaborator and … try and optimise the protocol”. This helps to ensure they get excellent results, every time.
very thorough with his work to ensure he has absolute confidence in every sample. “UV-Vis, fragment analyser, and Qubit. Several times” is his simple answer when I inquired what sample QC methods they used prior to sequencing. Mojca elaborated further by saying “sample prep can include shearing, size selection, short read eliminator* … all of these segments are QC’d in the library prep”. With all these checks in place, and from their vast experience they understand if a collaborator’s sample won’t sequence well and where needed the team will “go back to the collaborator and … try and optimise the protocol”. This helps to ensure they get excellent results, every time.
*Referring to the Short Read Eliminator Kit provided by Circulomics
Mixing projects and monitoring performance
Their PromethION isn’t only occupied with FTD samples, and Mojca’s team are very comfortable “mixing different types of projects” from other centres within VIB or other groups internally or externally (including universities across Belgium). According to the team, the majority of their sequencing is done on “human biosamples or animal models which are relative to the diseases we are studying … zebrafish also, a bit of yeast [and mouse]”, but applications for these samples can vary and they may have multiple experiments running on their PromethION at the same time. Wouter and Mojca reel off their current work; there is “cDNA-seq that we are testing on brain, … we have started testing the nanoNOMe protocol published from the lab of TIMP, … we also have a collaboration on the cancer genomes with the Center for Medical Genetics” in addition to running samples for a VIB PhD student working on epilepsy. They also use the MinION for testing projects before running on PromethION, such as a collection of bacterial genomes from another of the VIB centres. In any given period, they will have up to four projects running on the PromethION.
With all of these projects and samples running in parallel, Tim and Mojca are able to closely monitor performance thanks to the real-time nature of the data. Importantly, in addition to run setup and configuration, the MinKNOW software deployed across all of Oxford Nanopore’s sequencing devices provides real-time feedback on an experiment’s progression. For their barcoding experiments (when many samples are multiplexed on a single flow cell) the team at VIB use the MinKNOW graphs to check their barcode distributions, along with the read lengths from their samples. When they enable basecalling on the PromethION they can also monitor the quality scores and translocations speeds over the course of the run. Translocation speed refers to the speed at which the motor protein feeds DNA bases through the pore, which can impact read quality if it falls outside of a specified range.
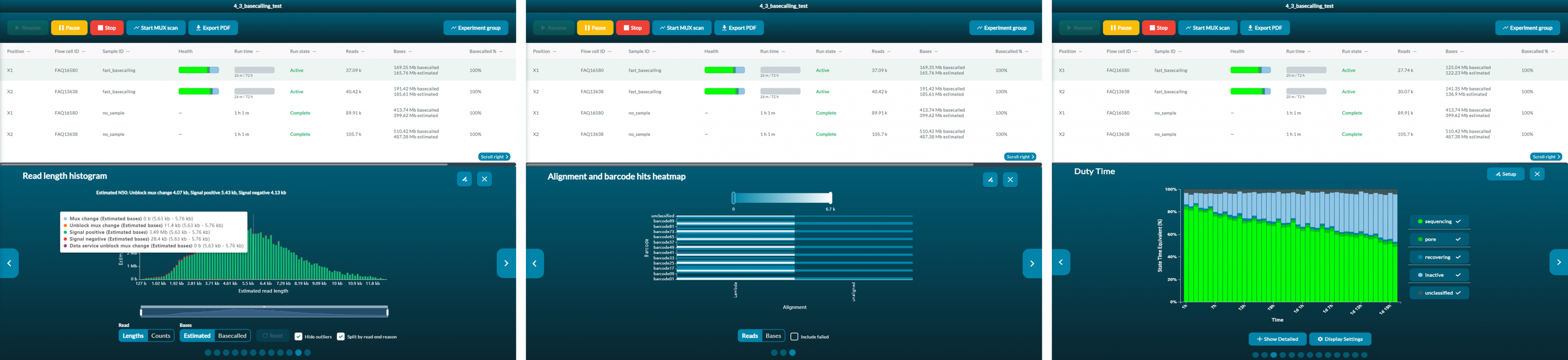
Once observed this can be remedied by flushing more fuel into the system, something the researchers at VIB do “almost always”. For some samples, they will monitor and intervene when required. For other samples, they do it on a fixed schedule, for example at 24 hour intervals (a PromethION flow cell has a default 72 hour run time, which can be shortened or extended as required). Sometimes, they also perform a nuclease flush, a process that can retrieve nanopores from an ‘unavailable’ state, making them available for sequencing once again when more library is added. “We normally prepare one library in excess that we can use for subsequent flushes … we start with about 200 femtomoles of sample and that gives us enough room to do three loadings of 40–50 femtomoles each”, says Tim. According to Mojca this is of great help as “we want to be economical … and really squeeze the maximum in quality and quantity [for every research project]”. It also helps to ensure Tim hits the desired yields per flow cell, with Wouter claiming “if it’s not 150 gigabases then Tim has some explaining to do!”.
Developing the methods
As aready alluded to, the consistency with which Mojca’s team can perform sequencing isn’t down to chance but rather dedicated work to discover and develop optimal techniques. On their large projects “we took quite some time to first optimise before we started”. An example of this was the FTD project where they not only optimised for brain tissue but also for different sub-types of brain tissue: “it’s all manual, we are not doing automated extractions”. They consistently trial extraction kits from Qiagen and Circulomics, with the latter of which Oxford Nanopore co-launched the Ultra-Long DNA Sequencing Kit and protocol for earlier this year. Whilst Circulomics is bead based, they see good results with Qiagen with the team commenting “it’s also the simplest type of method you have, just the normal silica-based extraction”.
Other researchers within VIB also understand the importance of optimising sample extraction methods to ensure optimal sequencing results. This is exemplified by Heloise Bastiaanse and her work investigating 700 poplar tree samples, for whom Mojca has nothing but priase: “It’s crazy – she did a marvelous job. Compared to some other samples that we get it’s really beautiful and pure”. Heloise is working on this project with Stephan Rombauts, both from the VIB-UGent Center for Plant Systems Biology. The details of this project are considerable — too much to be covered here — and will be captured in part two of this interview with the VIB nanopore sequencing experts.
Jonathan Pugh is an Associate Director at Oxford Nanopore Technologies and has spent almost 10 years developing and introducing nanopore sequencing technology
Want to learn more?
Read about the work of the VIB Center for Molecular Neurology
Meet the staff from the Neuromics Support Facility
See Wouter De Coster and his work on GitHub
Read more about using nanopore sequencing for structural variant detection






