New research algorithms yield accuracy gains for nanopore sequencing
Latest basecalling algorithms from Oxford Nanopore’s Research & Development teams show consistent improvement to raw, consensus and variant calling accuracies, with latest tools and methods reaching modal raw read accuracy of over 97% (and further improvements being actively worked on).
Basecalling, the process of converting raw signal data into a sequence, is a complex process undertaken by algorithms at the forefront of computational research. In collaboration with scientists from the Nanopore Community and drawing from related signal processing fields such as speech recognition, Oxford Nanopore continuously iterates on and refines these algorithms.
This has led to continuous accuracy improvements, manifested as improvements in raw read accuracy, consensus accuracy and variant calling accuracy over recent years. While raw read accuracy started at ~85% when nanopore sequencing was first introduced, >95% can now be achieved by users with the current version of the basecaller in production, leading to consensus accuracies of >99.99% (R9.4.1 chemistry) and >99.999% (R10.3 chemistry).
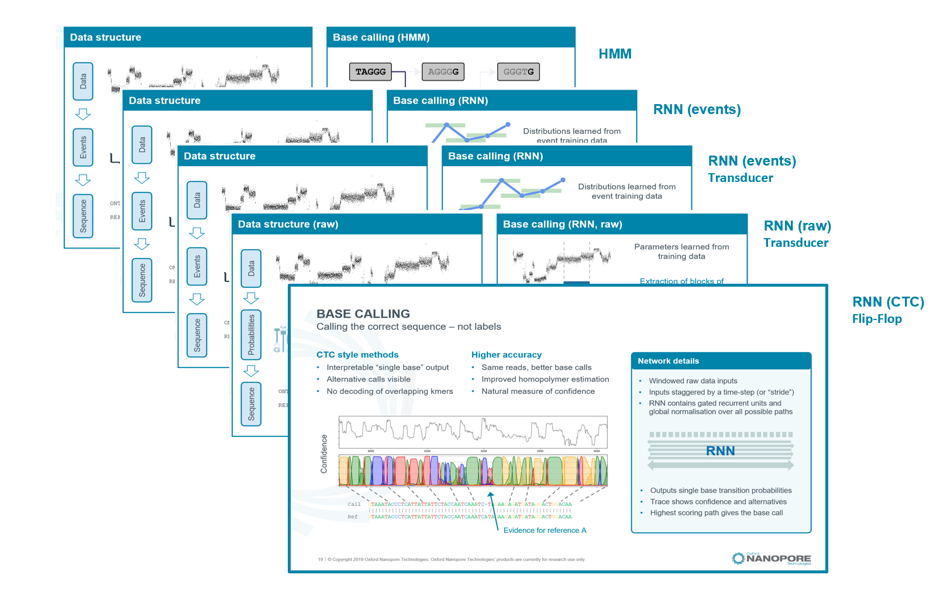
Figure 1: Evolution of basecalling algorithms since the release of MinION in 2014.
This week, Oxford Nanopore provided an update to its community of users (here (community login required)), outlining the most recent performance improvements. The latest releases of research basecallers are available on the Oxford Nanopore GitHub repository (here) and can be used by advanced users to preview and evaluate performance before these methods are integrated with nanopore devices. Two key updates have been provided:
- the first is an update to the flip-flop algorithm that currently underpins the basecalling architecture embedded in the product range.
- the second is an update of a newer algorithm (Bonito), first described in late 2019, that utilises a Convolutional Neural Network.
Both algorithms, when applied to the currently released flow cells and kits, achieve modal accuracies greater than 97 % (medians greater than 96 %). This represents a significant improvement of over 1 % vs the current production algorithm as assessed on an industry standard human genome (NA12878).
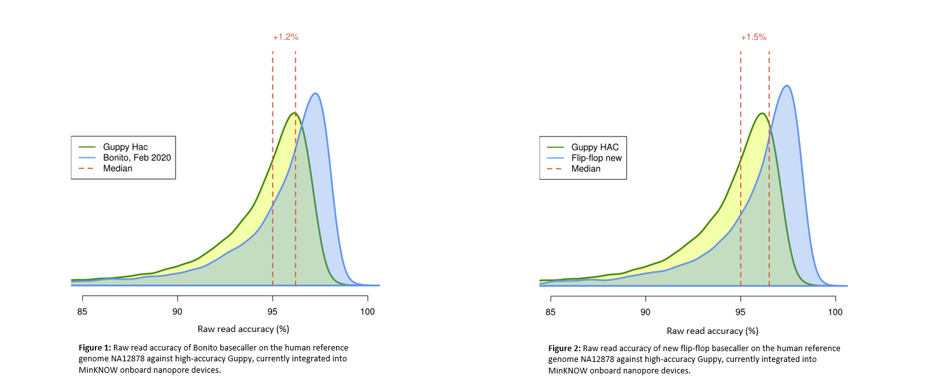
Figure 2: Performance improvement of Bonito and new flip-flop models when compared to the current production basecaller (Guppy HAC). Both projects show a shift in median accuracy greater than 1%.
The team are working with the community to assess the impact of this improvement which effectively represents a 20% reduction in error (from 5% error to ~3%) and look forward to hearing about some of the results over the coming weeks.
Access to cutting-edge performance
Oxford Nanopore continues to improve the nanopore sensing system, through updates to analytical methods and new chemistries. Users have access to high-quality, production-grade basecalling within MinKNOW - the instrument control software - for consistent and routine usage, including a fast option for where rapid time-to-result is critical. By providing open access to the newest advances in research tools, researchers have the ability to help shape the progress of nanopore technology whilst benefitting early from performance improvements.
Looking forward
Progress in these research projects demonstrates the rapid and high-achieving trajectory for nanopore data, with a number of avenues to pursue further developments. The Nanopore Community continues to push the boundaries of applications that are possible with the technology – for an in-depth look, see the latest publications and talks here.






