Blog: Long reads reveal small-scale structural variations in an allo-tetraploid crop plant
Harmeet Singh Chawla, from Justus Liebig University Giessen, discusses how he developed a pipeline using long nanopore reads to investigate genomic structural variation in the major crop Canola.
 Harmeet Singh ChawlaI am currently working as a PhD student at the Department of Plant Breeding at Justus Liebig University in Giessen. I did my Masters in Agrobiotechnology in Giessen. The main focus of my research is to analyse genome structural variation underlining various agronomically interesting traits in Canola. Recently, I have been involved in the development of SV detection pipelines, both at the wet lab and the informatics front, in Canola.
Harmeet Singh ChawlaI am currently working as a PhD student at the Department of Plant Breeding at Justus Liebig University in Giessen. I did my Masters in Agrobiotechnology in Giessen. The main focus of my research is to analyse genome structural variation underlining various agronomically interesting traits in Canola. Recently, I have been involved in the development of SV detection pipelines, both at the wet lab and the informatics front, in Canola. Long-read sequencing approaches such as Oxford Nanopore Technologies (ONT) have revolutionised the field of plant genomics. With ultra-long reads produced by nanopore sequencing platforms, it is now possible to access the most difficult parts of plant genomes which were almost invisible to short sequencing reads.
The quality and the length of nanopore sequencing reads depend heavily on the purity and integrity of the DNA. However, it is comparatively simple to isolate high molecular weight DNA from animals; plants often pose a challenge when it comes to extracting clean and long DNA molecules. This might be attributed to the presence of a plethora of secondary metabolites in plants. Secondary metabolites comprise a family of compounds that are not critical for the growth and development of a plant, but are crucial in conferring eco-geographical adaptability.
In our recent research (Chawla et al. 20201), we studied the impact of genome structural variations (SVs) on disease resistance and climatic adaptability in an allo-tetraploid crop plant Canola (Brassica napus) using long DNA sequencing reads. One of the major challenges to adapt nanopore sequencing to Canola was to obtain high molecular weight, clean DNA.
We tried different protocols – such as nuclei isolation (Sikorskaite et al. 20132), the standard Cetyl trimethylammonium bromide (CTAB) method (Doyle 19913) and the commercially available DNeasy Plant Mini Kit by Qiagen – to achieve high molecular weight DNA. While some of the methods, such as CTAB or the DNeasy Plant Mini Kit, can offer a good quality of DNA in terms of A260/280 and A260/230 ratios, they also often tend to introduce shearing, thereby lowering the read lengths of nanopore sequencing. Other methods based on nuclei isolation offer a very good read length distribution, but are often challenging to implement. Therefore, we developed a protocol based on Mayjonade et al. (2016)4, enabling us to isolate high molecular weight, ultra-pure DNA.
To further improve the read lengths, we introduced a size selection step, using the Circulomics Short Read Eliminator (SRE) kit, before the library prep for nanopore sequencing. The N50 for the size-selected libraries was found to be in between 25 and 30 kbp. These long reads enabled us to identify complex genome rearrangements up to 28 kbp in length (Figure 1). Another development that made nanopore sequencing even more lucrative for studying SVs in the Canola genome was the recent introduction of the DNase-based flow cell wash kits that have enabled us to achieve up to 30 Gbp from a single MinION Flow Cell.
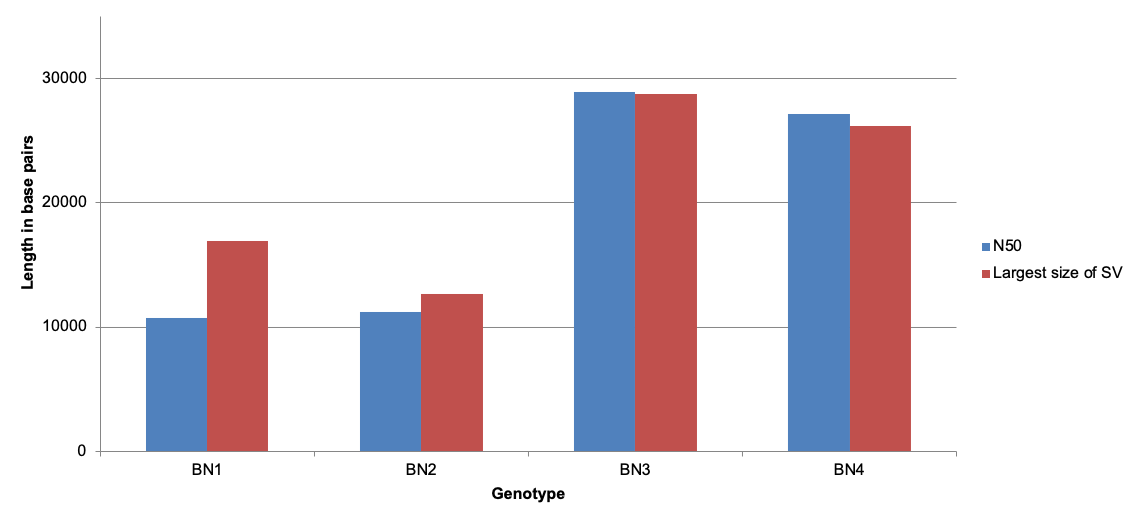
Using the long nanopore reads combined with recently developed algorithms for alignment (NGMLR) and SV calling (Sniffles) by Sedlazeck et al. (2018)5, we were able to identify small (30 to 10,000 bp) to mid-scale (10,000 to 30,000 bp) genomic rearrangements in the Canola genome and their impact on disease resistance and eco-geographical adaptation. We found that up to 10% of all genes were affected by small to mid-scale SV events.
Our results suggested that revisiting complex plant genomes using long-read nanopore sequencing might lead to the discovery of previously “hidden” functional gene variation, with major implications for trait regulation and crop improvement. As per our experience, we can surely recommend nanopore sequencing to decipher complex SVs in plant genomes. However, it should be taken into account that isolating high-quality DNA can be challenging for certain plant species, though in the last two years there has been an array of DNA isolation protocols specifically developed for various plant species. These protocols, with some optimisation, could potentially be used for dissecting complex traits in novel plant species.
References
- Chawla, Harmeet Singh; Lee, HueyTyng; Gabur, Iulian; Tamilselvan-Nattar-Amutha, Suriya; Obermeier, Christian; Schiessl, Sarah V. et al. (2020): Long-read sequencing reveals widespread intragenic structural variants in a recent allopolyploid crop plant. bioRxiv, 2020.01.27.915470. DOI: 10.1101/2020.01.27.915470.
- Sikorskaite, Sidona; Rajamäki, Minna-Liisa; Baniulis, Danas; Stanys, Vidmantas; Valkonen, Jari P. T. (2013): Protocol: Optimised methodology for isolation of nuclei from leaves of species in the Solanaceae and Rosaceae families. Plant Methods 9 (1), p. 31. DOI: 10.1186/1746-4811-9-31.
- Doyle, Jeffrey (1991): DNA Protocols for Plants. In Godfrey M. Hewitt, Andrew W. B. Johnston, J. Peter W. Young (Eds.): Molecular Techniques in Taxonomy. Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 283–293. Available online at https://doi.org/10.1007/978-3-642-83962-7_18.
- Mayjonade, Baptiste; Gouzy, Jérôme; Donnadieu, Cécile; Pouilly, Nicolas; Marande, William; Callot, Caroline et al. (2016): Extraction of high-molecular-weight genomic DNA for long-read sequencing of single molecules. BioTechniques 61 (4), pp. 203–205. DOI: 10.2144/000114460.
- Sedlazeck, Fritz J.; Rescheneder, Philipp; Smolka, Moritz; Fang, Han; Nattestad, Maria; Haeseler, Arndt von; Schatz, Michael C. (2018): Accurate detection of complex structural variations using single-molecule sequencing. Nat. Methods 15 (6), pp. 461–468. DOI: 10.1038/s41592-018-0001-7.






