Oxford Nanopore Support
Support
Can't find the answer you are looking for?
Talk to us using the support function.
How can I determine the number of reads that are being rejected due to adaptive sampling?
How can I determine the number of reads that are being rejected due to adaptive sampling?
You can determine the number of reads that are being rejected due to adaptive sampling via two methods:
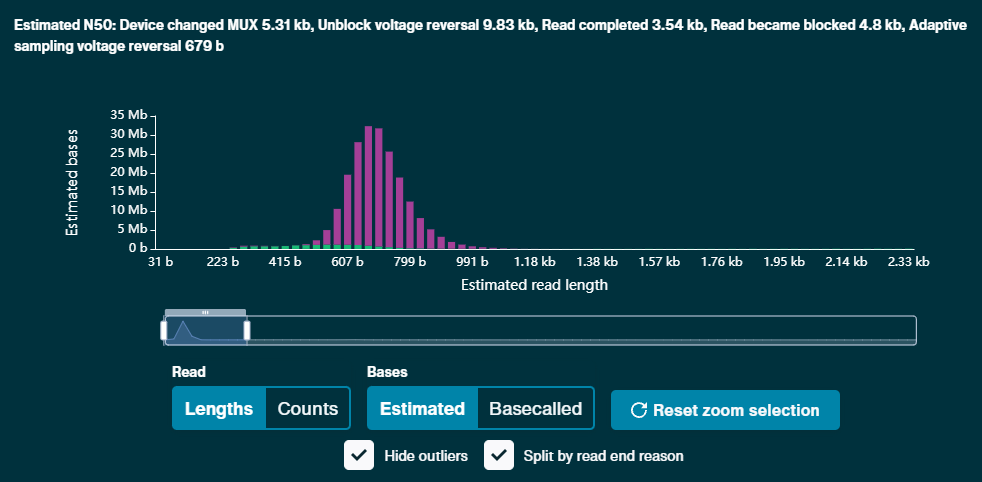
- During the run: in the Experiments tab in MinKNOW by opening the Read length histogram and ticking the box "Split by read end reason". If you are running in a mode where enough reads should be rejected to produce a peak of short reads, there should be a bimodal distribution with a peak at a length much lower than what you expect from the sample. The reads rejected by adaptive sampling will have the label "Adaptive sampling voltage reversal" and are shown in purple in the read length histogram. The image below zooms in on this peak of the rejected reads.
- Immediately after the sequencing run starts: please ensure that an
adaptive_samplingfolder has been generated inside your data output folder. This folder should contain two files:AS_decisions_x_x_x.csvfile andAS_timings_x_x_x.csvfile.
TheAS_decisions_x_x_x.csvfile contains information about the final decision that was taken by adaptive sampling for each read. Filtering this file by “action” column provides not only the number of accepted/rejected reads but also the specific readIDs of each read accepted and rejected. Accepted reads are marked as “sequence” and rejected reads are marked as “unblock”.






