The Nanopore Community Meeting opens with a full day of Masterclasses delivered by Oxford Nanopore’s experts
This year’s Nanopore Community Meeting got off to a busy start, with seven masterclasses walking the virtual audience through everything they need to know to perform their nanopore sequencing experiments. Oxford Nanopore’s own in-house sequencing experts delivered sample-to-answer training, with topics spanning from sample preparation, to sequencing, and finally data analysis. The online attendees also had the option to learn from a breadth of content on the virtual platform, from posters to pre-recorded Mini Theatre presentations and product information in the Live Lounge.
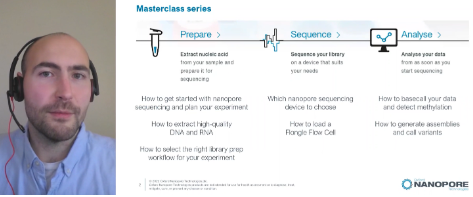
Here's a quick overview of the masterclass sessions, all of which are available to watch on-demand in the conference platform and, from next week, on our website.
How to get started with nanopore sequencing and plan your experiment

Kicking off the NCM 2022 masterclass series was Anupama Chandramouli, Field Applications Scientist. Anupama began by introducing how nanopore sequencing works and its key benefits across a wide range of applications, including its use by the Nanopore Community across the world, in the lab and in the field. Next, she shared an overview of the nanopore sequencing workflow – broken down into library prep, sequencing, and data analysis – and highlighted what to consider when planning your experiment. Wrapping up the session, Anupama walked viewers through what they’d need for their first nanopore sequencing experiment, and shared some useful online resources for getting started with nanopore sequencing.
How to extract high-quality DNA and RNA

Next, Vânia Costa, Technical Applications Scientist, guided us through the first stage of the sequencing workflow: extraction. She delivered expert advice on how to extract high-quality DNA and RNA from a wide range of samples, and how to check their quality. With the capacity to generate unrestricted read lengths with nanopore sequencing, Vânia introduced the significance of read lengths for different applications and how to optimise extraction by sample type, whether sequencing highly fragmented DNA with short-read mode or extracting ultra-high molecular-weight DNA for ultra-long-read sequencing. Vânia also described how a method can be adapted for high-throughput extraction. This was followed by best practices for storing and handling extracted nucleic acids, before finishing with an example covering extraction of DNA for metagenomic sequencing from environmental water samples. Vânia reminded us there is support at each step of the way on the Oxford Nanopore website and in the Nanopore Community.
How to select the right library prep workflow for your experiment

Covering the next stage of preparing samples for sequencing, Yan Yang, Technical Applications Scientist, delivered her masterclass on choosing a library preparation method to best suit your experimental goals. Yan described the different library preparation options available for nanopore sequencing of DNA, RNA, and cDNA — including preparation for sequencing at the single-cell level — as well as the difference between ligation and rapid chemistry. The applications and benefits of different sequencing techniques were discussed, including targeted approaches with PCR-free and PCR-based options. Yan also highlighted the recent Kit 14 chemistry from Oxford Nanopore, which has been optimised for both >99% accuracy and high sequencing yield for all read lengths. Finally, Yan highlighted the support for choosing a library prep method available online.
Which nanopore sequencing device to choose
Austin Compton, Technical Applications Specialist, talked us through the range of nanopore sequencing devices available, and the benefits of each. He described the different types of flow cells – MinION, PromethION, and Flongle – the differences between them, and which flow cells are compatible with which sequencing devices. He highlighted the versatility of the nanopore sequencing platform, with solutions for any scale of experiment or biological question, and shared some example applications and experiments. Austin then provided insight into how the goals of an experiment will determine the best flow cell and sequencing device combination to choose, with examples to help with the decision-making process. Austin also introduced adaptive sampling: a novel enrichment/depletion method that takes place entirely during real-time nanopore sequencing, with no special library prep needed.
How to load a Flongle Flow Cell

Next came the chance for viewers to get hands-on with the technology, in an interactive Flongle Flow Cell loading demo from Vanessa Michael, Sequencing QC Scientist. Vanessa began by going through the step-by-step process of loading a Flongle Flow Cell in detail, from preparation, to priming, to loading, to sealing. Then, it was the turn of viewers who had pre-registered to receive their demo flow cell loading kit, who could don their goggles and gloves to follow along with Vanessa in loading a Flongle Flow Cell themselves. Once viewers were familiar with the process, they were also shown how the process works for MinION and our highest-yield PromethION Flow Cells.
How to basecall your data and detect methylation

Beginning the masterclasses on analysis, Jessica Anderson, Field Applications Scientist, explained how to basecall nanopore sequencing data and call methylation. Jessica introduced the basics of how nanopore sequencing data analysis works and introduced the file formats involved. She described the options available for analysis of nanopore sequencing data and then provided an introduction on how to use the software ideal for those who are newer to data analysis: MinKNOW, EPI2ME, and EPI2ME Labs. Finally, Jessica outlined how to call and analyse methylation data from PCR-free nanopore sequencing datasets She explained how methylation can be directly detected in native molecules – without the need for special library prep – and can be called alongside nucleotide sequence in analysis.
How to generate assemblies and call variants

Last but not least was Matt Attreed, Technical Applications Scientist, who continued the theme of data analysis with an introduction to assembly and variant calling. He covered the use of assembly across multiple experiment types, including small and large genome assembly and assembly of genomes from metagenomic samples, with representative analysis workflows for each. Next, he described how to call SNVs and structural variants (SVs) in nanopore sequencing data, using the latest available pipelines and analysis tools. This included an introduction to human-variation-workflow: a streamlined pipeline enabling basecalling, small variant calling, SV calling, and modified base calling in the human genome. Finally, Matt highlighted the options available for the analysis of transcriptomic data, including analysis at the single-cell level.
This year’s conference is a hybrid event and you can still register for online attendance for the live presentations over the next two days here: nanoporetech.com/ncm22






